

Tesseract-OCR样本训练方法
Tesseract-OCR样本训练方法
一、简介
Tesseract是一个开源的OCR=Optical Character Recognition=光学字符识别=引擎=可以识别多种格式的图像文件并将其转换成文本=目前已支持60多种语言=包括中文=。 Tesseract最初由HP公司开发=后来由Google维护。
二、下载
1.从https://github.com/UB-Mannheim/tesseract/wiki下载tesseract安装包,目前较新的版本是tesseract-ocr-w64-setup-v4.0.0.20181030.exe。
2.从https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/下载jTessBoxEditor训练工具=目前较新的版本是jTessBoxEditor-2.2.0.zip。
3.由于jTessBoxEditor是用Java开发的=需要安装Java虚拟机才能运行。从https://**.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html下载Java JDK,目前较新的版本事jdk-8u191-windows-x64.exe。
三、安装tesseract
1.双击tesseract-ocr-setup-4.00.00dev.exe运行。

2.点击Next。

3.I accept the terms of the License Agreement前的复选框打勾=点击Next。

4.Install for anyone using this computer前的复选框打勾=点击Next。

5.选择需要安装的内容=点击Next。

6.点击Browse…选择安装路径=默认安装在C:\Program Files(x86)\Tesseract-OCR=点击Next。

7.点击Install。

8.等待安装完成。

9.点击Next。

10.Show README前的复选框取消打勾=点击Finish。

四、安装Java JDK
1.双击jdk-8u191-windows-x64.exe运行。

2.点击下一步。

3.点击更改。

4.输入安装路径后=点击确定。

5.点击下一步。

6.等待安装完成。

7.点击关闭。

五、配置Java环境变量
1.此电脑右键。

2. 点击属性。

3.点击高级系统设置。

4.选择高级->环境变量。

5.点击新建。

6.变量名输入J**A_HOME=变量值输入JDK安装目录=点击确定。

7.系统变量中,选择Path=点击编辑。

8.点击新建。

9.输入%J**A_HOME%\bin=点击确定。
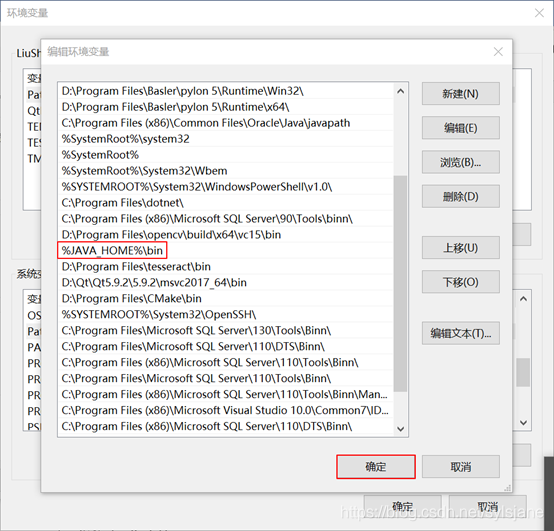
10.点击确定。

11.点击确定。

12.重启电脑。
六、安装jTessBoxEditor
1.解压

2.双击jTessBoxEditor-2.2.0

3.双击jTessBoxEditor

4.双击jTessBoxEditor,jar运行

5.出现以下界面则安装成功。

七、制作训练样本
1. 运行jTessBoxEditor工具=点击Tools。

2.点击Merge TIFF。

3.文件类型选择All I**ge Files=选择样本图片=点击打开。

4.文件名输入num.font.exp0.tif=文件类型选择TIFF=点击保存。

5.点击确定。

6. 将num.font.exp0.tif文件**到Tesseract-OCR安装目录。

7. 生成Box File文件。打开cmd命令行=以管理员身份运行。

8.进入Tesseract-OCR安装目录。

9.执行命令:
tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop **kebox
生成的box文件为num.font.exp0.box=box文件为Tesseract识别出的字符及其坐标。
注=Make Box File 文件名有一定的格式=不能随便乱取名字=命令格式为=
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop **kebox
其中lang为语言名称=fontname为字体名称=num为序号=可以随便定义。

10. 将上一步生成的.box和.tif样本文件放在同一目录。我是放在Tesseract-OCR默认安装目录下。

11.运行jTessBoxEditor工具=点击Box Editor。

12.点击Open。

13.选择之前生成的num.font.exp0.tif=点击打开。

14. 可以看出有些字符识别的位置不准确=可以通过该工具手动对每张图片中识别错误的字符和位置进行校正。校正完成后保存即可。
注: 这里必须修改识别错误的字符=否则做出来的traineddata文件也是错的。可以在下面的界面中修改并保存=也可以直接在traineddata文件中修改。

15. 定义字体特征文件。创建一个名称为font_properties的字体特征文件。font_properties不含有BOM头=文件内容格式如下=
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
其中fontname为字体名称=必须与[lang].[fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0=表示字体是否具有这些属性。
这里在样本图片所在目录下创建一个名称为font_properties的文件=用记事本打开=输入以下下内容=
font 0 0 0 0 0
这里全取值为0=表示字体不是粗体、斜体等等。

16. 生成语言文件。在样本图片所在目录下创建一个批处理文件=输入如下内容:
rem 执行改批处理前先要目录下创建font_properties文件
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.

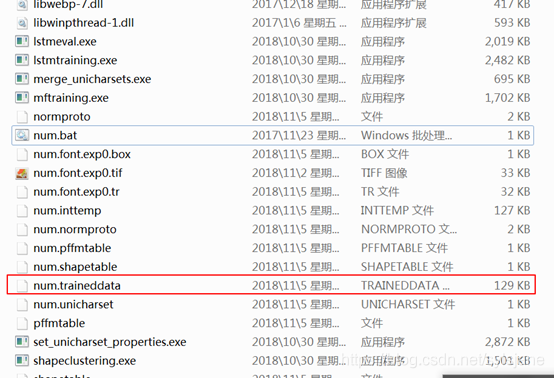
17. 执行批处理文件, num.traineddata便是最终生成的语言文件,将生成的num.traineddata拷贝到程序的样本文件夹里,就可以使用了。
转载:感谢您阅览,转载请注明文章出处“来源从小爱孤峰知识网:一个分享知识和生活随笔记录的知识小站”。
链接:Tesseract-OCR样本训练方法http://www.gufeng7.com/engines/543.html
联系:如果侵犯了你的权益请来信告知我们删除。邮箱:119882116@qq.com



